Language Data Commons of Australia Program
LDaCA uses RO-Crate as an interchange and archive format for language data, and is providing data discovery portals and API access to data using RO-Crate-centric APIs. The LDaCA Program architecture consists of a set of modular services; data preservation/archiving, APIs for delivery, access control and a discovery portal for data and analysis tools as well as automated container-based notebook environments to run analytics via the Australian Text Analytics Platform (which is a component of the broader program).
The data portal for the ATAP platform is the first released product, there will be more data portals which provide access to a broader range of data in 2023.
RO-Crate in the LDaCA Program
RO-Crate is the central metadata standard for all data within the LDaCA environment. The use of detached RO-crates has been utilised to navigating centralised API resources, rather than considering RO-Crate only as a standalone publication on the Web.
Archiving
RO-Crate provides a consistent metadata model for long term archiving and preservation and is used to store archival copies of language datasets using the Oxford Common File Layout.
API Access
The LDaCA project provide access-controlled API access to data using the Oni tool. Access control is important for language data as it is created by and collected from humans who have intellectual property rights over the data and some of he content may be confidential
For example, this query looks for RO-Crates which package objects, with a conformsTo property from the Language Data Commons RO-Crate profile: https://w3id.org/ldac/profile#Collection. This demonstration returns 10 results from a total of 27 collections on the service as of 2024-07-09 (truncated here), which can then be fetched using the url property.
> curl --location --request GET 'http://data.ldaca.edu.au/api/object?conformsTo=https://w3id.org/ldac/profile%23Collection' | jq
{
{
"total": 27,
"data": [
{
"crateId": "arcp://name,deafblind",
"license": "#Australian-Deafblind-Signing-Corpus_interim",
"name": "Australian Deafblind Signing Corpus",
"description": "Australian Deafblind Signing Corpus captures free conversations between consenting participants as well as discussions at two workshops. The vast majority of the free conversations in the corpus are between two deafblind people, but we also recorded conversations between our focal participant Heather Lawson and five sighted deaf people, as well as another deafblind-deaf conversation for comparative purposes. Conversations were often collected opportunistically: as part of wider deafblind events, consenting participants were approached and asked to bring a friend for a social chat (on a topic of their own choosing) that would be filmed and added to the corpus. In all cases participants knew each other prior to the recording taking place (often having known each other for decades). The workshop data comes from sessions organised by the project team to bring deafblind signers together to discuss metalinguistic issues, such as how they preferred to adapt certain features of visual Auslan for tactile perception (e.g. avoiding confusion when signing numbers – see Willoughby et al 2020). At our workshop each deafblind person worked with interpreters to access what was being signed by others in the room. As such there are multiple video files for the workshop, each focused on a different deafblind participant and their interpreting team.\nData was collected between 2011-19, and collection and annotation was principally funded through an Australian Research Council Discovery Project. Melbourne deafblind woman Heather Lawson has been a research team member and focal informant for the project, with the core project team also including Louisa Willoughby, Meredith Bartlett, Jim Hlavac, Howard Manns, Shimako Iwasaki and Dennis Witcombe. The deafblind signers who appear in the corpus all have a significant dual sensory (vision and hearing) loss and use Auslan as their primary means of receptive communication. The participants overwhelmingly have degenerative eye conditions (such as Retinitis Pigmentosa), meaning all but one had enough sight as children to learn Auslan through visual perception. They have varied levels of residual vision but all use tactile signing under at least some lighting conditions. Those with sufficient residual vision sometimes use visual perception of signing in the corpus study, and we also see participants moving to more and more tactile reception over time as their vision deteriorates. It is important to note that even in instances where participants do use visual perception of sign languages they have marked vision impairments (including extreme tunnel vision) so are unlikely to perceive facial expressions or other bodily movements outside of their narrow field of vision.",
"objectRoot": "/opt/storage/oni/ocfl/arcp_name_deafblind/__object__",
"locked": false,
"createdAt": "2024-06-06T05:34:22.587Z",
"updatedAt": "2024-06-06T05:34:22.587Z",
"recordType": [
"Dataset",
"RepositoryCollection"
],
"conformsTo": "https://w3id.org/ldac/profile#Collection",
"record": {
"name": "Australian Deafblind Signing Corpus",
"license": "#Australian-Deafblind-Signing-Corpus_interim",
"description": "Australian Deafblind Signing Corpus captures free conversations between consenting participants as well as discussions at two workshops. The vast majority of the free conversations in the corpus are between two deafblind people, but we also recorded conversations between our focal participant Heather Lawson and five sighted deaf people, as well as another deafblind-deaf conversation for comparative purposes. Conversations were often collected opportunistically: as part of wider deafblind events, consenting participants were approached and asked to bring a friend for a social chat (on a topic of their own choosing) that would be filmed and added to the corpus. In all cases participants knew each other prior to the recording taking place (often having known each other for decades). The workshop data comes from sessions organised by the project team to bring deafblind signers together to discuss metalinguistic issues, such as how they preferred to adapt certain features of visual Auslan for tactile perception (e.g. avoiding confusion when signing numbers – see Willoughby et al 2020). At our workshop each deafblind person worked with interpreters to access what was being signed by others in the room. As such there are multiple video files for the workshop, each focused on a different deafblind participant and their interpreting team.\nData was collected between 2011-19, and collection and annotation was principally funded through an Australian Research Council Discovery Project. Melbourne deafblind woman Heather Lawson has been a research team member and focal informant for the project, with the core project team also including Louisa Willoughby, Meredith Bartlett, Jim Hlavac, Howard Manns, Shimako Iwasaki and Dennis Witcombe. The deafblind signers who appear in the corpus all have a significant dual sensory (vision and hearing) loss and use Auslan as their primary means of receptive communication. The participants overwhelmingly have degenerative eye conditions (such as Retinitis Pigmentosa), meaning all but one had enough sight as children to learn Auslan through visual perception. They have varied levels of residual vision but all use tactile signing under at least some lighting conditions. Those with sufficient residual vision sometimes use visual perception of signing in the corpus study, and we also see participants moving to more and more tactile reception over time as their vision deteriorates. It is important to note that even in instances where participants do use visual perception of sign languages they have marked vision impairments (including extreme tunnel vision) so are unlikely to perceive facial expressions or other bodily movements outside of their narrow field of vision."
},
"url": "https://data.ldaca.edu.au/api/object/arcp%3A%2F%2Fname%2Cdeafblind?meta"
},
{
"crateId": "arcp://name,doi10.26181%2F23089559",
"license": "https://creativecommons.org/licenses/by/4.0/",
"name": "The La Trobe Corpus of Spoken Australian English",
"description": "The La Trobe Corpus of Spoken Australian English (LTCSAusE) comprises a collection of six recordings and transcriptions of spoken interaction amongst Australian speakers of English (some in conversation with native French speakers speaking English) made in Melbourne from 2001 to 2002. The recordings are transcribed using a combination of the Santa Barbara and conversation analysis transcription conventions. This collection was previously accessible online via the Australian National Corpus (AusNC), an initiative managed by Griffith University between 2012 and 2023.",
"objectRoot": "/opt/storage/oni/ocfl/arcp_name_doi10.26181%2F23089559/__object__",
"locked": false,
"createdAt": "2024-06-06T05:34:22.887Z",
"updatedAt": "2024-06-06T05:34:22.887Z",
"recordType": [
"Dataset",
"RepositoryCollection"
],
"conformsTo": "https://w3id.org/ldac/profile#Collection",
"record": {
"name": "The La Trobe Corpus of Spoken Australian English",
"license": "https://creativecommons.org/licenses/by/4.0/",
"description": "The La Trobe Corpus of Spoken Australian English (LTCSAusE) comprises a collection of six recordings and transcriptions of spoken interaction amongst Australian speakers of English (some in conversation with native French speakers speaking English) made in Melbourne from 2001 to 2002. The recordings are transcribed using a combination of the Santa Barbara and conversation analysis transcription conventions. This collection was previously accessible online via the Australian National Corpus (AusNC), an initiative managed by Griffith University between 2012 and 2023."
},
"url": "https://data.ldaca.edu.au/api/object/arcp%3A%2F%2Fname%2Cdoi10.26181%252F23089559?meta"
},
]
}
RO-Crate metadata for a collection can be fetched using the url property returned above.
> curl https://data.ldaca.edu.au/api/object/arcp%3A%2F%2Fname%2Cdeafblind\?meta | jq
Click to see the full crate metadata
{
"@context": [
"https://w3id.org/ro/crate/1.1/context",
{
"@vocab": "http://schema.org/"
},
{
"rightsHolder": "http://purl.org/dc/terms/rightsHolder"
},
{
"subjectLanguage": "http://schema.org/subjectLanguage"
},
{
"ldac": "https://w3id.org/ldac/terms#",
"Annotation": "https://w3id.org/ldac/terms#Annotation",
"Coded": "https://w3id.org/ldac/terms#Coded",
"CollectionEvent": "https://w3id.org/ldac/terms#CollectionEvent",
"CollectionProtocol": "https://w3id.org/ldac/terms#CollectionProtocol",
"DataDepositLicense": "https://w3id.org/ldac/terms#DataDepositLicense",
"DataLicense": "https://w3id.org/ldac/terms#DataLicense",
"DerivedMaterial": "https://w3id.org/ldac/terms#DerivedMaterial",
"Dialogue": "https://w3id.org/ldac/terms#Dialogue",
"Drama": "https://w3id.org/ldac/terms#Drama",
"ElicitationTask": "https://w3id.org/ldac/terms#ElicitationTask",
"Formulaic": "https://w3id.org/ldac/terms#Formulaic",
"Gesture": "https://w3id.org/ldac/terms#Gesture",
"Handwritten": "https://w3id.org/ldac/terms#Handwritten",
"IndexTypes": "https://w3id.org/ldac/terms#IndexTypes",
"Informational": "https://w3id.org/ldac/terms#Informational",
"Interview": "https://w3id.org/ldac/terms#Interview",
"Lexicon": "https://w3id.org/ldac/terms#Lexicon",
"Ludic": "https://w3id.org/ldac/terms#Ludic",
"Narrative": "https://w3id.org/ldac/terms#Narrative",
"Orthographic": "https://w3id.org/ldac/terms#Orthographic",
"PartOfSpeech": "https://w3id.org/ldac/terms#PartOfSpeech",
"Phonemic": "https://w3id.org/ldac/terms#Phonemic",
"Phonetic": "https://w3id.org/ldac/terms#Phonetic",
"Phonological": "https://w3id.org/ldac/terms#Phonological",
"PrimaryMaterial": "https://w3id.org/ldac/terms#PrimaryMaterial",
"Procedural": "https://w3id.org/ldac/terms#Procedural",
"Prosodic": "https://w3id.org/ldac/terms#Prosodic",
"Report": "https://w3id.org/ldac/terms#Report",
"Semantic": "https://w3id.org/ldac/terms#Semantic",
"Session": "https://w3id.org/ldac/terms#Session",
"SignedLanguage": "https://w3id.org/ldac/terms#SignedLanguage",
"Song": "https://w3id.org/ldac/terms#Song",
"SpokenLanguage": "https://w3id.org/ldac/terms#SpokenLanguage",
"Syntactic": "https://w3id.org/ldac/terms#Syntactic",
"MaterialSelectionCriteria": "https://w3id.org/ldac/terms#MaterialSelectionCriteria",
"Thesaurus": "https://w3id.org/ldac/terms#Thesaurus",
"Transcription": "https://w3id.org/ldac/terms#Transcription",
"Translation": "https://w3id.org/ldac/terms#Translation",
"Typeset": "https://w3id.org/ldac/terms#Typeset",
"Typewritten": "https://w3id.org/ldac/terms#Typewritten",
"WrittenLanguage": "https://w3id.org/ldac/terms#WrittenLanguage",
"accessControlList": "https://w3id.org/ldac/terms#accessControlList",
"annotationOf": "https://w3id.org/ldac/terms#annotationOf",
"annotationType": "https://w3id.org/ldac/terms#annotationType",
"annotator": "https://w3id.org/ldac/terms#annotator",
"author": "https://w3id.org/ldac/terms#author",
"authorizationWorkflow": "https://w3id.org/ldac/terms#authorizationWorkflow",
"channels": "https://w3id.org/ldac/terms#channels",
"collectionEventType": "https://w3id.org/ldac/terms#collectionEventType",
"collectionProtocolType": "https://w3id.org/ldac/terms#collectionProtocolType",
"compiler": "https://w3id.org/ldac/terms#compiler",
"consultant": "https://w3id.org/ldac/terms#consultant",
"dataInputter": "https://w3id.org/ldac/terms#dataInputter",
"depositor": "https://w3id.org/ldac/terms#depositor",
"derivationOf": "https://w3id.org/ldac/terms#derivationOf",
"developer": "https://w3id.org/ldac/terms#developer",
"doi": "https://w3id.org/ldac/terms#doi",
"editor": "https://w3id.org/ldac/terms#editor",
"geoJSON": "https://w3id.org/ldac/terms#geoJSON",
"hasAnnotation": "https://w3id.org/ldac/terms#hasAnnotation",
"hasCollectionProtocol": "https://w3id.org/ldac/terms#hasCollectionProtocol",
"hasDerivation": "https://w3id.org/ldac/terms#hasDerivation",
"illustrator": "https://w3id.org/ldac/terms#illustrator",
"indexableText": "https://w3id.org/ldac/terms#indexableText",
"interpreter": "https://w3id.org/ldac/terms#interpreter",
"interviewee": "https://w3id.org/ldac/terms#interviewee",
"interviewer": "https://w3id.org/ldac/terms#interviewer",
"isDeIdentified": "https://w3id.org/ldac/terms#isDeIdentified",
"subjectLanguage": "https://w3id.org/ldac/terms#subjectLanguage",
"communicationMode": "https://w3id.org/ldac/terms#communicationMode",
"openAccessIndex": "https://w3id.org/ldac/terms#openAccessIndex",
"participant": "https://w3id.org/ldac/terms#participant",
"performer": "https://w3id.org/ldac/terms#performer",
"photographer": "https://w3id.org/ldac/terms#photographer",
"recorder": "https://w3id.org/ldac/terms#recorder",
"register": "https://w3id.org/ldac/terms#register",
"researchParticipant": "https://w3id.org/ldac/terms#researchParticipant",
"researcher": "https://w3id.org/ldac/terms#researcher",
"responder": "https://w3id.org/ldac/terms#responder",
"signer": "https://w3id.org/ldac/terms#signer",
"singer": "https://w3id.org/ldac/terms#singer",
"speaker": "https://w3id.org/ldac/terms#speaker",
"sponsor": "https://w3id.org/ldac/terms#sponsor",
"transcriber": "https://w3id.org/ldac/terms#transcriber",
"translator": "https://w3id.org/ldac/terms#translator",
"dateFreeText": "https://w3id.org/ldac/terms#dateFreeText",
"MaterialTypes": "https://w3id.org/ldac/terms#MaterialTypes",
"materialType": "https://w3id.org/ldac/terms#materialType",
"linguisticGenre": "https://w3id.org/ldac/terms#linguisticGenre",
"access": "https://w3id.org/ldac/terms#access",
"reviewDate": "https://w3id.org/ldac/terms#reviewDate",
"CommunicationModeTerms": "https://w3id.org/ldac/terms#CommunicationModeTerms",
"LinguisticGenreTerms": "https://w3id.org/ldac/terms#LinguisticGenreTerms",
"CollectionProtocolTypeTerms": "https://w3id.org/ldac/terms#CollectionProtocolTypeTerms",
"WrittenLanguageTypeTerms": "https://w3id.org/ldac/terms#WrittenLanguageTypeTerms",
"FullText": "https://w3id.org/ldac/terms#FullText",
"AnnotationTypeTerms": "https://w3id.org/ldac/terms#AnnotationTypeTerms",
"CollectionEventTypeTerms": "https://w3id.org/ldac/terms#CollectionEventTypeTerms",
"DataReuseLicense": "https://w3id.org/ldac/terms#DataReuseLicense",
"AuthorizationWorkflows": "https://w3id.org/ldac/terms#AuthorizationWorkflows",
"WhistledLanguage": "https://w3id.org/ldac/terms#WhistledLanguage",
"Oratory": "https://w3id.org/ldac/terms#Oratory",
"Gestural": "https://w3id.org/ldac/terms#Gestural",
"AgreeToTerms": "https://w3id.org/ldac/terms#AgreeToTerms",
"AuthorizationByApplication": "https://w3id.org/ldac/terms#AuthorizationByApplication",
"AuthorizationByInvitation": "https://w3id.org/ldac/terms#AuthorizationByInvitation",
"SelfAuthorization": "https://w3id.org/ldac/terms#SelfAuthorization",
"AccessControlList": "https://w3id.org/ldac/terms#AccessControlList",
"AccessTypes": "https://w3id.org/ldac/terms#AccessTypes",
"AuthorizedAccess": "https://w3id.org/ldac/terms#AuthorizedAccess",
"OpenAccess": "https://w3id.org/ldac/terms#OpenAccess"
}
],
"@graph": [
{
"@id": "https://ror.org/02bfwt286",
"@type": "Organization",
"name": "Monash University"
},
{
"@id": "https://orcid.org/0000-0001-6823-0791",
"@type": "Person",
"name": "Louisa Willoughby",
"affiliation": {
"@id": "https://ror.org/02bfwt286"
},
"description": ""
},
{
"@id": "https://glottolog.org/resource/languoid/id/stan1293",
"@type": "Language",
"languageCode": "stan1293",
"name": "English",
"geo": {
"@id": "_geo-glottolog-stan1293"
},
"source": "Glottolog",
"sameAs": {
"@id": "https://www.ethnologue.com/language/eng"
},
"alternateName": [
"English (Standard Southern British)",
"Englisch",
"Anglais moderne [fr]",
"English [en]",
"Inglese moderno [it]",
"Inglês moderno [pt]",
"Modern English [en]",
"Moderna angla lingvo [eo]",
"Moderne engelsk [no]",
"Modernes Englisch [de]",
"Nyengelska [sv]",
"anglais [fr]",
"თანამედროვე ინგლისური პერიოდი [ka]",
"現代英語 [zh]",
"近代英語 [ja]"
],
"iso639-3": "eng"
},
{
"@id": "_geo-glottolog-stan1293",
"@type": "Geometry",
"name": "Geographical coverage for English",
"asWKT": "POINT(-1.0 53.0)"
},
{
"@id": "https://glottolog.org/resource/languoid/id/aust1271",
"@type": "Language",
"languageCode": "aust1271",
"name": "Auslan",
"geo": {
"@id": "_geo-glottolog-aust1271"
},
"source": "Glottolog",
"sameAs": {
"@id": "https://www.ethnologue.com/language/asf"
},
"alternateName": [
"Australian Sign Language",
"Auslan [en]",
"Australian Sign Language [en]",
"Australski znakovni jezik [hr]",
"Língua de Sinais Australiana [pt]"
],
"iso639-3": "asf"
},
{
"@id": "_geo-glottolog-aust1271",
"@type": "Geometry",
"name": "Geographical coverage for Auslan",
"asWKT": "POINT(145.0 -30.0)"
},
{
"@id": "#Australian-Deafblind-Signing-Corpus_interim",
"@type": "CreativeWork",
"name": "ADSC interim licence",
"description": "Contact Louisa Willoughby (louisa.willoughby@monash.edu) to request access."
},
{
"@id": "https://orcid.org/0000-0003-3008-4535",
"@type": "Person",
"name": "Meredith Bartlett"
},
{
"@id": "https://orcid.org/0000-0002-6593-7203",
"@type": "Person",
"name": "Shimako Iwasaki"
},
{
"@id": "https://orcid.org/0000-0002-6266-0982",
"@type": "Person",
"name": "Howard Manns"
},
{
"@id": "#Researcher_DW",
"@type": "Person",
"name": "Dennis Witcombe"
},
{
"@id": "ro-crate-metadata.json",
"@type": "CreativeWork",
"identifier": "ro-crate-metadata.json",
"about": {
"@id": "arcp://name,deafblind"
},
"conformsTo": {
"@id": "https://w3id.org/ldac/profile#Collection"
}
},
{
"@id": "arcp://name,deafblind",
"@type": [
"Dataset",
"RepositoryCollection"
],
"conformsTo": {
"@id": "https://w3id.org/ldac/profile#Collection"
},
"name": "Australian Deafblind Signing Corpus",
"description": "Australian Deafblind Signing Corpus captures free conversations between consenting participants as well as discussions at two workshops. The vast majority of the free conversations in the corpus are between two deafblind people, but we also recorded conversations between our focal participant Heather Lawson and five sighted deaf people, as well as another deafblind-deaf conversation for comparative purposes. Conversations were often collected opportunistically: as part of wider deafblind events, consenting participants were approached and asked to bring a friend for a social chat (on a topic of their own choosing) that would be filmed and added to the corpus. In all cases participants knew each other prior to the recording taking place (often having known each other for decades). The workshop data comes from sessions organised by the project team to bring deafblind signers together to discuss metalinguistic issues, such as how they preferred to adapt certain features of visual Auslan for tactile perception (e.g. avoiding confusion when signing numbers – see Willoughby et al 2020). At our workshop each deafblind person worked with interpreters to access what was being signed by others in the room. As such there are multiple video files for the workshop, each focused on a different deafblind participant and their interpreting team.\nData was collected between 2011-19, and collection and annotation was principally funded through an Australian Research Council Discovery Project. Melbourne deafblind woman Heather Lawson has been a research team member and focal informant for the project, with the core project team also including Louisa Willoughby, Meredith Bartlett, Jim Hlavac, Howard Manns, Shimako Iwasaki and Dennis Witcombe. The deafblind signers who appear in the corpus all have a significant dual sensory (vision and hearing) loss and use Auslan as their primary means of receptive communication. The participants overwhelmingly have degenerative eye conditions (such as Retinitis Pigmentosa), meaning all but one had enough sight as children to learn Auslan through visual perception. They have varied levels of residual vision but all use tactile signing under at least some lighting conditions. Those with sufficient residual vision sometimes use visual perception of signing in the corpus study, and we also see participants moving to more and more tactile reception over time as their vision deteriorates. It is important to note that even in instances where participants do use visual perception of sign languages they have marked vision impairments (including extreme tunnel vision) so are unlikely to perceive facial expressions or other bodily movements outside of their narrow field of vision.",
"publisher": {
"@id": "https://ror.org/02bfwt286"
},
"accountablePerson": {
"@id": "https://orcid.org/0000-0001-6823-0791"
},
"rightsHolder": {
"@id": "https://orcid.org/0000-0001-6823-0791"
},
"isAccessibleForFree": [],
"inLanguage": {
"@id": "https://glottolog.org/resource/languoid/id/stan1293"
},
"subjectLanguage": [
{
"@id": "https://glottolog.org/resource/languoid/id/aust1271"
},
{
"@id": "https://glottolog.org/resource/languoid/id/stan1293"
}
],
"license": {
"@id": "#Australian-Deafblind-Signing-Corpus_interim"
},
"temporalCoverage": "2011/2018",
"author": [
{
"@id": "https://orcid.org/0000-0001-6823-0791"
},
{
"@id": "https://orcid.org/0000-0003-3008-4535"
},
{
"@id": "https://orcid.org/0000-0002-6593-7203"
},
{
"@id": "https://orcid.org/0000-0002-6266-0982"
},
{
"@id": "#Researcher_DW"
}
],
"usageInfo": "This is a forthcoming collection. Contact Louisa Willoughby (louisa.willoughby@monash.edu) to request access.",
"hasPart": [],
"hasMember": [],
"identifier": {
"@id": "_:local-id:LDaCA:arcp://name,deafblind"
}
},
{
"@id": "#En",
"@type": "GeoCoordinates",
"name": "Geographical coverage for En",
"geojson": "{\"type\":\"Feature\",\"properties\":{\"name\":\"En\"},\"geometry\":{\"type\":\"Point\",\"coordinates\":[\"106.167\",\"22.8386\"]}}"
},
{
"@id": "_:local-id:LDaCA:arcp://name,deafblind",
"@type": "PropertyValue",
"value": "arcp://name,deafblind",
"name": "LDaCA"
},
{
"@id": "git+https://github.com/Arkisto-Platform/oni-ocfl.git",
"@type": "SoftwareSourceCode",
"name": "git+https://github.com/Arkisto-Platform/oni-ocfl.git",
"description": "Oni ocfl tools",
"programmingLanguage": {
"@id": "https://en.wikipedia.org/wiki/Node.js"
}
},
{
"@id": "#provenance",
"name": "Created RO-Crate using oni-ocfl",
"@type": "CreateAction",
"instrument": {
"@id": "git+https://github.com/Arkisto-Platform/oni-ocfl.git"
},
"result": {
"@id": "ro-crate-metadata.json"
}
}
]
}
Discovery portals
The structural API described above is used to build discovery and access portals which use the metadata from RO-Crate objects to generate an Elasticsearch index and a web site to search and browse the RO-Crate-packaged data.
The portal/index system us highly configurable to work with differently structured RO-Crate data.
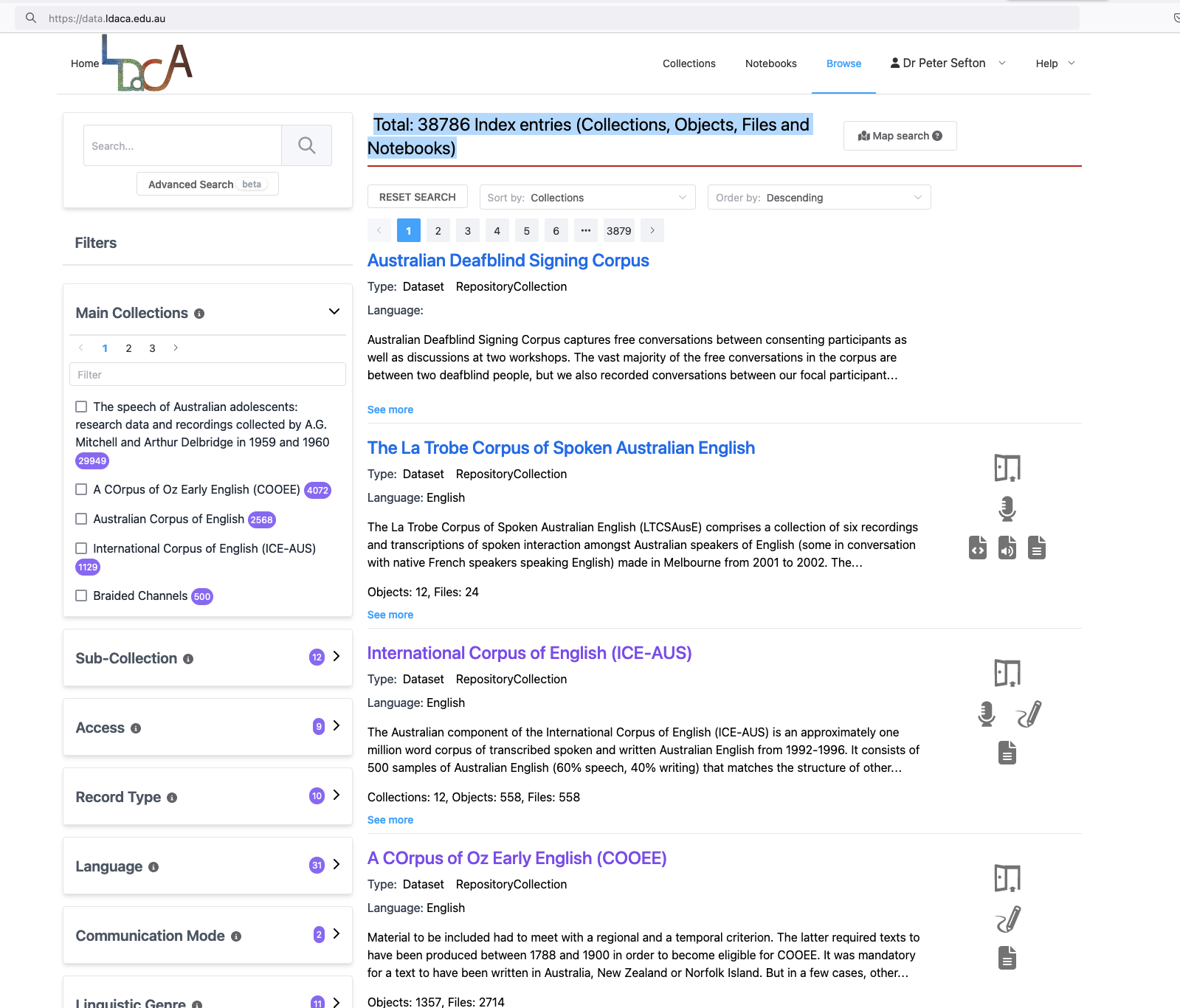
Screenshot of LDaCA data portal showing that it contains 38786 Index entries (Collections, Objects, Files and Notebooks)