2025-10-13: The RO-Crate website and specification superseded this website after 2020. These pages are no longer maintained.
We strongly recommend that new Research Object users adopt the RO-Crate specification.
BioCompute Objects (BCO) is a community-driven project backed by the FDA (US Food and Drug Administration) and George Washington University to standardize exchange of High-Throughput-Sequencing workflows for regulatory submissions between FDA, pharma, bioinformatics platform providers and researchers.
![]() Members of the Research Object team (Carole Goble, Stian Soiland-Reyes, Michael R Crusoe) have been collaborating closely with the rest of the BCO community since 2016, in particular covering the integration of BCO with existing standards like Research Object, W3C PROV and Common Workflow Language.
Vahan Simonyan from FDA presented BioCompute Objects to the GA4GH Cloud workstream webinar on 2017-11-27.
The below blog post is based on an extract of Vahan’s slides modulated to cover my thoughts on the role of Research Objects with BCOs.
Members of the Research Object team (Carole Goble, Stian Soiland-Reyes, Michael R Crusoe) have been collaborating closely with the rest of the BCO community since 2016, in particular covering the integration of BCO with existing standards like Research Object, W3C PROV and Common Workflow Language.
Vahan Simonyan from FDA presented BioCompute Objects to the GA4GH Cloud workstream webinar on 2017-11-27.
The below blog post is based on an extract of Vahan’s slides modulated to cover my thoughts on the role of Research Objects with BCOs.
-
Introduction
-
Model of BioCompute Objects
-
JSON of BioCompute Object
-
Links and references
-
Packaging it up: Research Object
-
Take part!
Introduction
There is a particular challenge for regulatory bodies like FDA in areas like personalized medicine, as to review and approve the bioinformatics side they need to inspect and in some cases replicate the computational analytical workflow. The challenge here is not just the normal reproducibility thing about packaging software and providing required datasets, but also for human understanding of what has been done, by expressing the higher level steps of the workflow, their parameter spaces and algorithm settings. (PMC5510742)
Model of BioCompute Objects
At the heart of the BCO is a domain-specific object model which capture this essential information without going in details of the actual execution:
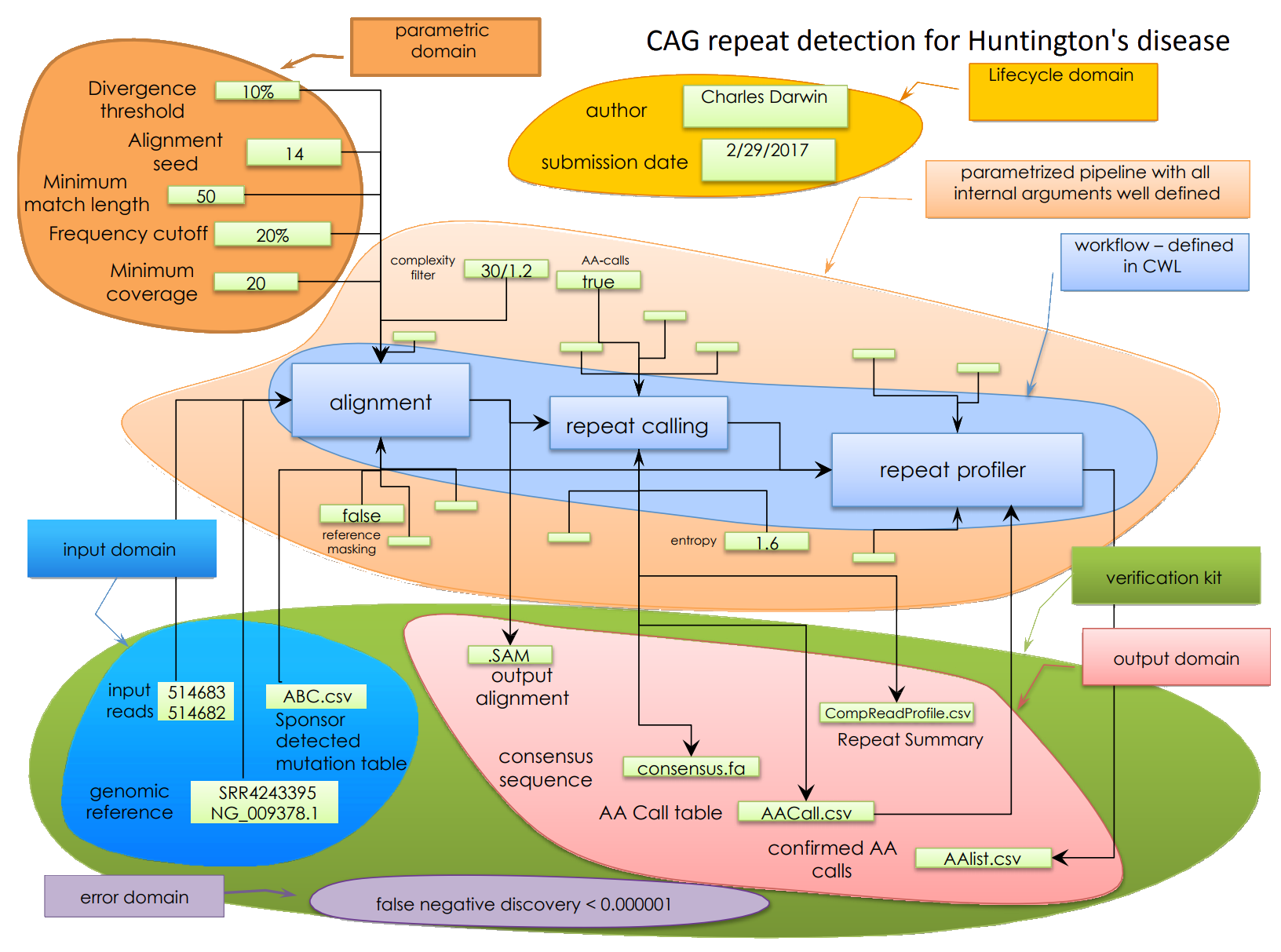 The full background and development of the BioCompute Object model is detailed in the recent BCO community paper (https://doi.org/10.1101/191783).
The full background and development of the BioCompute Object model is detailed in the recent BCO community paper (https://doi.org/10.1101/191783).
JSON of BioCompute Object
The BCO is expressed as a JSON format, which also includes additional metadata and external identifiers.
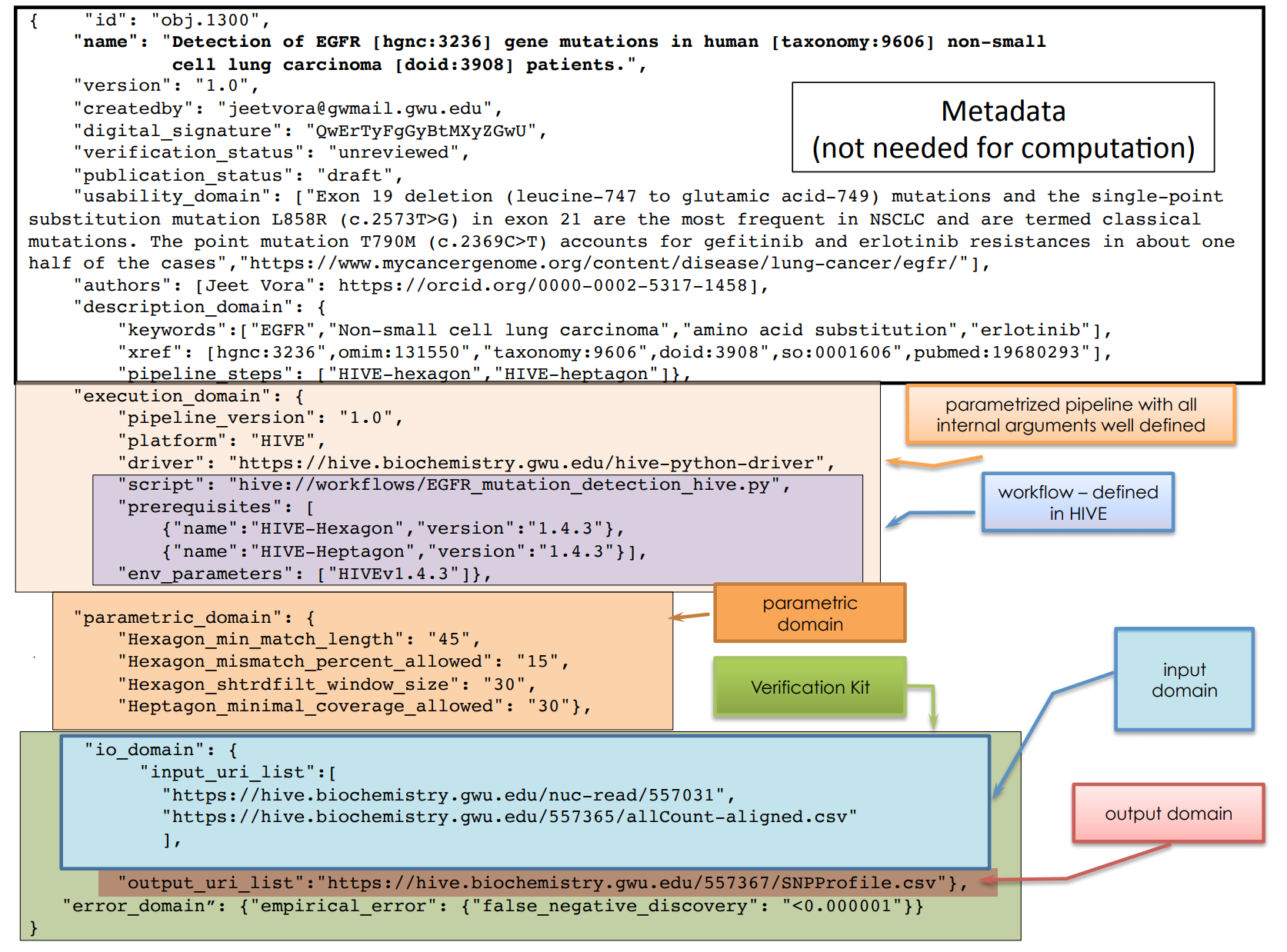 If we look at this JSON briefly, it is split into metadata, a brief overview of the pipeline with arguments and scripts. The actual workflow definition is defined outside. In addition we define parametric domain, and for verification the input/output domains. This allows inspection to see what is the scope of the analysis. For more details, see the first release of the BCO Specification Document (https://osf.io/zm97b/).
If we look at this JSON briefly, it is split into metadata, a brief overview of the pipeline with arguments and scripts. The actual workflow definition is defined outside. In addition we define parametric domain, and for verification the input/output domains. This allows inspection to see what is the scope of the analysis. For more details, see the first release of the BCO Specification Document (https://osf.io/zm97b/).
Links and references
Looking deeper, many of the BioCompute entries are actually external links or references:  The authors and contributors are identified using ORCID, which is a de-facto standard identifier for researchers.
The cross-references are provided with identifiers.org prefixes.
The pipeline can be provided in any language, like Python, or it be specified using Common Workflow Language – which gives portability as well as capturing execution environment, e.g. which Python version to use for the scripts.
The referenced data files are of course in multiple formats, like CSV or – for sequencing data - more specific formats like SAM.
Now while the BCO references these resources in several places in its JSON structure, some may also be indirectly referenced. For instance the CWL workflow might reference particular Docker images that capture the Python version to use.
W3C PROV files might be provided, which can explain more detailed provenance of workflows (e.g. using wfprov); this might however become specific to the workflow engine used, and might not be directly identified all the resources seen in the BCO.
While we can identify authors with ORCID, they might author different parts of the BCO. If you made a clever Python script used by a BCO, then it is only FAIR that you should be attributed – even if you were nowhere in the vicinity when the BCO was later created.
So let’s have a look at all the direct and indirect links:
The authors and contributors are identified using ORCID, which is a de-facto standard identifier for researchers.
The cross-references are provided with identifiers.org prefixes.
The pipeline can be provided in any language, like Python, or it be specified using Common Workflow Language – which gives portability as well as capturing execution environment, e.g. which Python version to use for the scripts.
The referenced data files are of course in multiple formats, like CSV or – for sequencing data - more specific formats like SAM.
Now while the BCO references these resources in several places in its JSON structure, some may also be indirectly referenced. For instance the CWL workflow might reference particular Docker images that capture the Python version to use.
W3C PROV files might be provided, which can explain more detailed provenance of workflows (e.g. using wfprov); this might however become specific to the workflow engine used, and might not be directly identified all the resources seen in the BCO.
While we can identify authors with ORCID, they might author different parts of the BCO. If you made a clever Python script used by a BCO, then it is only FAIR that you should be attributed – even if you were nowhere in the vicinity when the BCO was later created.
So let’s have a look at all the direct and indirect links:
 So you can think of the pink, green and blue arrows in the figure above as each giving partial picture of what is the whole BioCompute Objects.
So you can think of the pink, green and blue arrows in the figure above as each giving partial picture of what is the whole BioCompute Objects.
Packaging it up: Research Object
So we’ve identified that there are multiple references, attributions, provenance traces and annotations to keep track of in a BioCompute Object.
There is also the question of how to move the BCO around – the JSON has many external references as well as relative references to plain files – how can you capture it all without understanding all of the BCO spec?
We are looking at using the BagIt Research Objects for this purpose.
Bag-It is a digital archive format used by Library of Congress and digital repositories. It handles checksums and completeness of files, even if they are large or external.
Research Object (RO) (https://doi.org/10.1016/j.websem.2015.01.003) is a model for capturing and describing research outputs; embedding data, executables, publications, metadata, provenance and annotations. Although it is a general model, ROs have been used in particular for capturing reproducible workflows.
The combination of these, ro-bagit aka BDBags has recently been used by the NIH-BD2K-funded BDDS project for transferring and archiving very large HTS datasets (https://doi.org/10.1109/BigData.2016.7840618 [preprint]) in a location-independent way (the BDDS group has recently been awarded new funding under NIH Data Commons), so we hope BDBags could be a good choice also to to package and archive BCOs.
The below figure illustrates how the manifest of the Research Object (manifest.json) ties the BioCompute Object together:
 The Research Object manifest (https://doi.org/10.5281/zenodo.12586) is in JSON-LD format – so it is Linked Data – but you don’t have to know unless you really want to – for everyone else it just JSON.
The manifest aggregates all the other resources, including the BCO, but also external resources as well as outside references like identifiers.org.
The aggregation also provide attribution and provenance of each resource, so they get the credit they deserve. This is of course also important for regulatory purposes, e.g. to check if the latest version of a tool was used.
An important aspect of research objects is also to capture annotations, using the W3C Web Annotation Model. This allows any part of the BCO to be further described; textually or semantically; so you are not limited to what is supported by the specification of BCO or Research Object. In particular this might be where community-driven standards like BioSchemas can be used.
The Research Object manifest (https://doi.org/10.5281/zenodo.12586) is in JSON-LD format – so it is Linked Data – but you don’t have to know unless you really want to – for everyone else it just JSON.
The manifest aggregates all the other resources, including the BCO, but also external resources as well as outside references like identifiers.org.
The aggregation also provide attribution and provenance of each resource, so they get the credit they deserve. This is of course also important for regulatory purposes, e.g. to check if the latest version of a tool was used.
An important aspect of research objects is also to capture annotations, using the W3C Web Annotation Model. This allows any part of the BCO to be further described; textually or semantically; so you are not limited to what is supported by the specification of BCO or Research Object. In particular this might be where community-driven standards like BioSchemas can be used.
 So to finish off with a Logo Soup™ – while BioCompute Objects are developed with domain-specific requirements in mind, and in a way is “yet another standard” – it is also fitting into a landscape of well-established standards, technologies and communities.
In particular our BCO team includes people who are or have also worked on Common Workflow Language, Research Object, BioSchemas, ORCID, PROV and GA4GH.
So we’re not developing BCO in isolation, but with these integrations and collaboration as pragmatic parts of our future direction.
So to finish off with a Logo Soup™ – while BioCompute Objects are developed with domain-specific requirements in mind, and in a way is “yet another standard” – it is also fitting into a landscape of well-established standards, technologies and communities.
In particular our BCO team includes people who are or have also worked on Common Workflow Language, Research Object, BioSchemas, ORCID, PROV and GA4GH.
So we’re not developing BCO in isolation, but with these integrations and collaboration as pragmatic parts of our future direction.
Take part!
Do you want to take part in shaping Biocompute Objects? See the BioCompute Project Space at Open Science Framework, or join our community WebEx meetings (for call details, contact Charles Hadley King at: hadley_king@gwu.edu)